6月24日,广东高考成绩放榜,社交媒体被“查分名场面”“考生喜报”刷屏,而一场专属于AI大模型的“高考成绩”也悄然出炉。
日前,羊城晚报教育发展研究院采用2026高考试题,对千问-3.7-Max、讯飞星火-X2、豆包-2.1-Turbo、DeepSeek-V4-Pro、GLM-5.2、ChatGPT-5.5-Pro、Claude-Opus-4.8、Gemini-3.5-flash等8款国内外主流大模型进行了横向测试,邀请2名资深教师独立盲评。
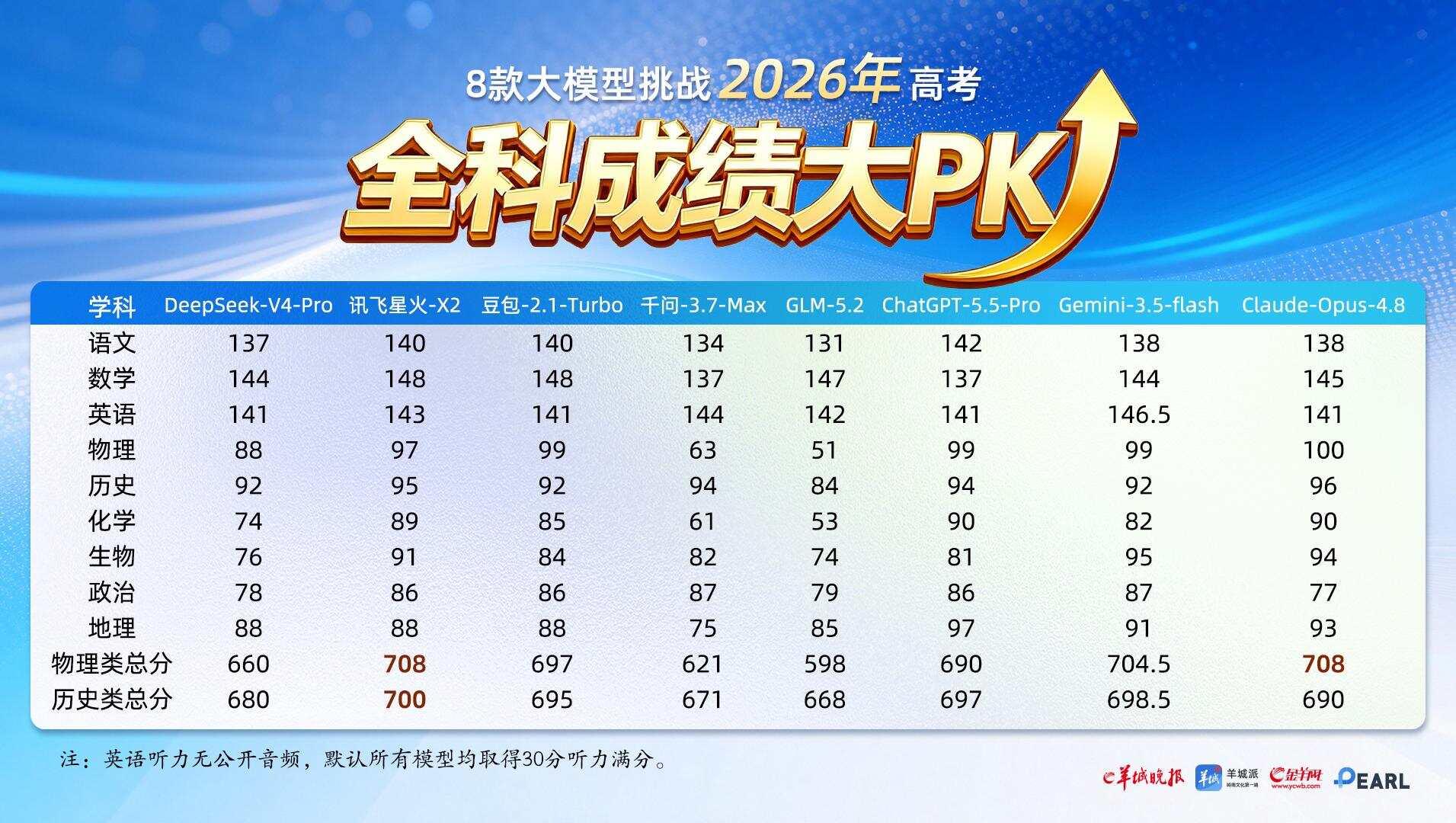
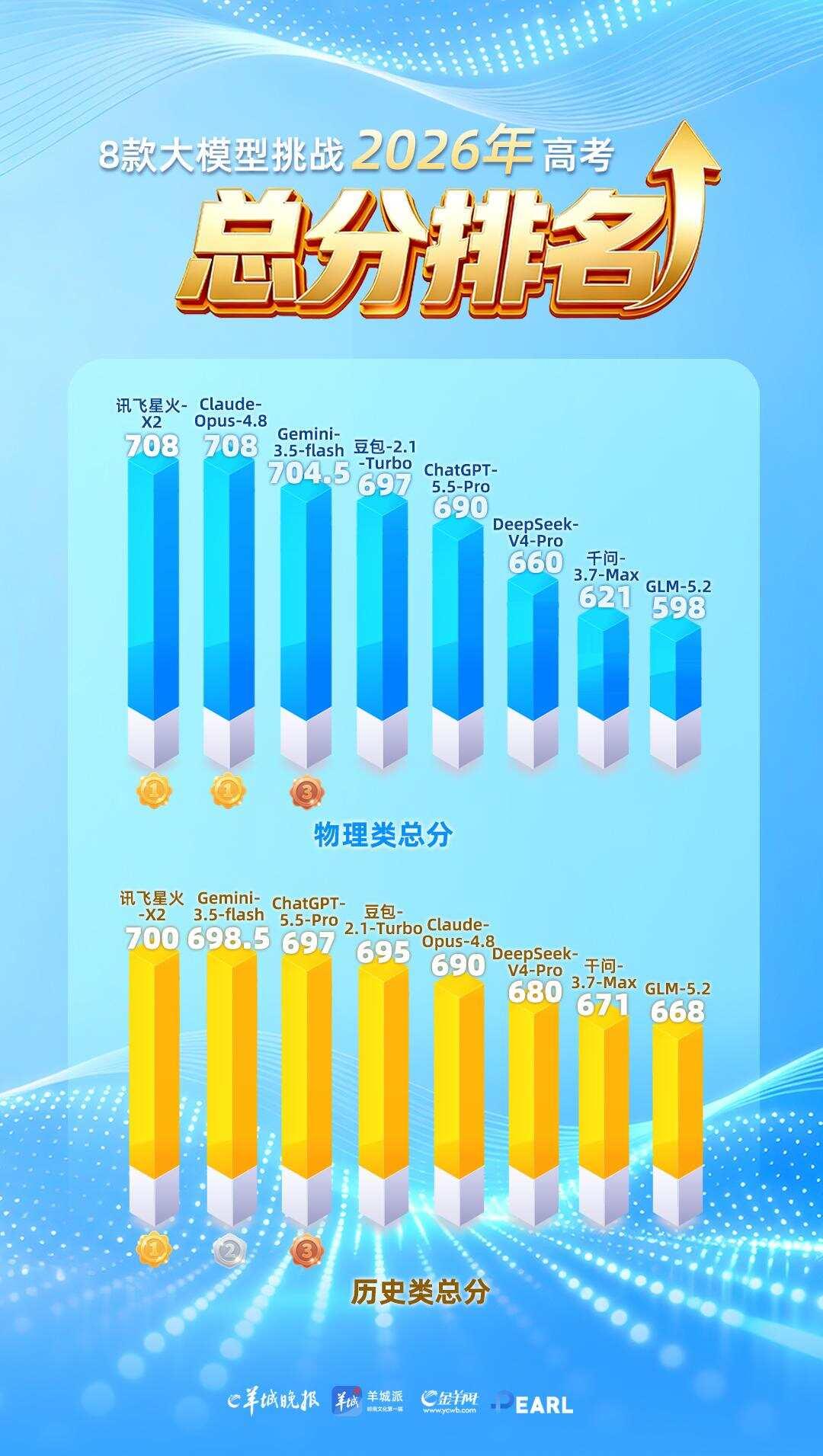
结果显示,Claude-Opus-4.8和讯飞星火-X2的物理类总分708分,并列第一,进入广东屏蔽生行列;历史类总分上700分只有讯飞星火-X2,也进入广东屏蔽生行列。豆包-2.1-Turbo、DeepSeek-V4-Pro、GLM-5.2、ChatGPT-5.5-Pro、Claude-Opus-4.8、Gemini-3.5-flash等模型也在部分科目中表现突出,呈现出不同的能力侧重。
 8款大模型挑战2026年高考全科成绩大PK
8款大模型挑战2026年高考全科成绩大PK
本次测评语文、数学、英语三科统一使用新课标I卷;选考科目均采用广东省自主命题试卷,仅地理科目除外——因测评开展阶段暂未获取完整广东地理真题,故选用命题难度、出题逻辑与广东卷高度贴近的山东地理卷作为替代素材。测评时,各模型均选用网页端最优版本,并将深度思考模式调至最高。所有模型使用相同提示词,回答内容均为一次性生成,不追加提问,也不进行人工修改。在总分计算上,按照历史类和物理类分科方式统计,采用大部分考生选择的组合进行计算(历史类:语数英三科+历史+政治地理;物理类:语数英三科+物理+化学生物)的“3+1+2”形式。阅卷评分严格对标高考官方评分细则,客观题按标准统一判分,作文、解答等主观大题由两名资深教师独立盲评打分。
需要说明的是,用于测评的题目为根据网络流出的多个版本交叉验证后的试题(可能存在与真题试卷不完全相符的情况,但不影响测评进行,所有大模型“考生”使用的均为相同题目)。
从最终成绩看,头部大模型之间的竞争已经不再局限于单点知识问答,而是进入到多学科综合能力的比拼:既考查知识覆盖,也考察复杂推理、长文本理解、规范表达和跨学科迁移能力。
总分表现:头部模型差距收窄,均衡能力成为拉分关键
从总分维度来看,主流头部大模型整体得分差距不大,最终排名高低更多由全科稳定性决定。物理类总分榜单中,Claude-Opus-4.8和讯飞星火-X2并列第一,其后依次为Gemini-3.5-flash、豆包-2.1-Turbo、ChatGPT-5.5-Pro、DeepSeek-V4-Pro、千问-3.7-Max、GLM-5.2,各模型分档得分各有区分。
历史类前五名依次为讯飞星火-X2、Gemini-3.5-flash、ChatGPT-5.5-Pro、豆包-2.1-Turbo、Claude-Opus-4.8。
整体来看,海外大模型 ChatGPT-5.5-Pro、Claude-Opus-4.8在长文本输出、议论文论述表达上基础实力突出,无明显短板学科。GLM-5.2历史类和物理类全科得分存在明显偏科现象,顶尖难题突破能力略有不足。放到全科测评中,能否在语文、数学、英语、物理(或历史)及选考科目之间保持均衡,成为影响总分排名的重要因素。讯飞星火-X2此次在历史和物理两类总分中均取得领先,主要得益于其在语言理解、数理推理和综合分析等不同任务中的相对均衡表现,而非单一科目的明显拉动。
 8款大模型挑战2026年高考总分排名
8款大模型挑战2026年高考总分排名
单科表现:各模型能力侧重不同,语文作文和数学压轴题区分度较高
从单科成绩来看,各模型在不同科目上表现出明显的路线差异。语文、英语等语言类科目中,头部模型总分差距相对较小,分差主要来自作文立意、结构组织和表达稳定性;数学、物理等科目则区分度更高,尤其是压轴题和多步骤推导题,更考验模型的复杂推理与过程规范能力。
语文科目中,议论文写作和现代文阅读是主要分水岭。ChatGPT-5.5-Pro与Claude-Opus-4.8长于框架搭建和逻辑推进,文章结构成熟完整。千问-3.7-Max、豆包-2.1-Turbo在材料归纳和中文语境理解上表现较为稳定。GLM-5.2在结构化作答方面能够较好回应设问要求,但选题偏常规化,新颖度不足。讯飞星火-X2各模块得分相对均衡,作文时代立意高远、逻辑完整、论据新颖,有细节,文风沉稳思辨。
 千问-3.7-Max获得了此次作文测评最高分57分。扣分原因:字数1228,扣1分;结尾升华不足,立意一般,扣2分。
千问-3.7-Max获得了此次作文测评最高分57分。扣分原因:字数1228,扣1分;结尾升华不足,立意一般,扣2分。
 GLM-5.2获得了此次作文测评最低分53分。扣分原因:素材抗疫、救灾等偏常规化,新颖度不足,扣1分;素材多为概括罗列,缺少具体的个体案例做细节支撑,扣2分;议论深度不足,扣2分,立意“英雄是挺身而出的凡人” 普通不出彩,扣2分。
GLM-5.2获得了此次作文测评最低分53分。扣分原因:素材抗疫、救灾等偏常规化,新颖度不足,扣1分;素材多为概括罗列,缺少具体的个体案例做细节支撑,扣2分;议论深度不足,扣2分,立意“英雄是挺身而出的凡人” 普通不出彩,扣2分。
数学方面,基础题与中档题多数模型准确率接近,差距主要体现在压轴题。部分模型在长链条推理中容易出现步骤跳跃或逻辑断裂,有的会引入超纲解法,虽能得出正确答案,但面临过程分扣除的风险。讯飞星火-X2在这类题目中解题步骤更规范、关键推导更完整,过程分、结果分和推理清晰度三个维度保持较好一致性。DeepSeek-V4-Pro在部分数理题中也展现了较强的推导能力。GLM-5.2在中档题和部分推理题中的表现较稳定,但在高难度长链条题目上仍有提升空间。
英语科目各模型在客观题和阅读理解上差距不大,分差主要来自写作。ChatGPT-5.5-Pro、Claude-Opus-4.8、Gemini-3.5-flash在表达流畅度和句式丰富度上具备优势;千问-3.7-Max、豆包-2.1-Turbo则更偏保守,但内容要点覆盖完整,能满足基本任务要求。
物理、化学和生物这几科中,物理侧重建模与多步推导,化学侧重实验推理和概念辨析,生物强调材料理解与知识整合。不同模型在三科中的表现不尽一致,得分差异主要取决于模型能否将读题、推理和规范作答完整串联起来。讯飞星火-X2在物理、化学、生物三科中的得分较为均衡,解题过程中读题、建模、推导和作答各环节衔接顺畅,失分点较少。
政治、历史、地理均要求较强的材料解读和结构化表达能力。ChatGPT-5.5-Pro和Claude-Opus-4.8在长文本组织中表现突出;千问-3.7-Max、豆包-2.1-Turbo在知识调用和表达规范性上相对稳定。
专家:技术倒逼数学教育深层变革
针对此次AI大模型做高考题的结果,专家是如何看待的呢?数学教育家、广东省高考研究会首任理事长、广东省初等数学学会首任会长吴康在接受记者采访时表示,AI的解题能力正高速进化,“我们要客观看待这一结果,更值得思考的是我们教育如何进行深层次的变革。”
作为数学教育家,吴康长期跟踪测试AI的数学解题能力。他介绍,2025年初的大模型尚难以应对高难度题型,仅过去1年多,其解题覆盖范围与难度就已大幅提升,不同知识分支的进步虽有差异,但整体进化速度惊人。他预测,约一年后,AI即可在普通高考数学卷中取得满分。在他看来,AI将逐步替代低层次计算劳动,让人类得以将精力投向更高阶的数学思考与研究,本质是帮助人类站在技术肩膀上持续进阶。
针对“AI会做题,学数学还有什么用”的疑问,吴康表示,数学学习的核心价值在于锻炼思维、推理、分析、辨别与计算能力,而非单纯掌握计算技巧。正如当年珠算被计算器取代一样,未来基础运算、公式记忆等机械性内容可交由AI完成,人类学习的重心将向更深层的数学原理与思维方法迁移。他预判,未来10年,中小学数学课本将迎来显著调整,更高阶的大学数学内容会逐步下放,基础教育的知识深度将整体提升。
针对当前高考数学日趋灵活、反套路的趋势,吴康直言,传统题海战术已失效,而不少地方的教研仍陷入“空对空”的形式主义,重论文职称、轻解题实战。他提出,AI解题能力的大幅提升,将推动学校教育和教研体系的深层转型。“必须打造专业的教研团队深耕难题与创新题型,厘清题目来龙去脉与考场应对路径,同时还要改革教师评价导向,让荣誉与职称评定向解题能力、教学实效倾斜。”
谈及数学思维与刷题熟练度的关系,吴康认为,二者是辩证统一的关系:熟练度是基础,但不能陷入低层次机械重复。他主张螺旋上升式训练,以思维提升带动熟练度增长,让学生在每道题中都能吸收营养、迭代能力,做到熟能生巧、巧中带熟,在攻克难题的过程中实现真正的能力成长。
记者手记
教育的复杂性,从来不是一道可以一键求解的方程
近年来,通用大模型在高考中拿高分已从技术奇观变为常态,舆论热度虽有减退,但核心追问仍在:AI的高考高分,到底意味着什么?是机器智力超越人类的佐证,还是教育体系将要颠覆的信号?
要回答这个问题,需先厘清一个关键区别:同等分数下,人与AI属于完全不同的维度。一名考生考出700分,是十二年寒窗、情绪抗压、知识内化、临场应变叠加后的成长结果,分数背后是少年的试错、疲惫、热爱与取舍,是完整人格支撑下的综合答卷,它承载着个人命运、家庭期许与人生选择。而AI拿下同样的分数,只是算法基于海量题库、语料数据和答题范式完成的一场概率最优推理——它不知备考之苦、不晓落榜之痛,不懂文字共情,更无升学渴望。这份高分没有人生重量,只是算力与数据拟合的投影。
因此,一个普遍焦虑应当消解:AI考高分,从不意味着取代学生或淘汰教师。高考试卷中客观标准化题型,恰好只是大模型更容易发挥优势的板块。但高考分数只覆盖教育的窄切面。真正的教育,要培养的是思辨、共情、创造与价值判断的完整人格,这些远非AI所能触及。
抛开考场上的噱头,AI高考高分真正的社会价值,指向的是普惠教育的补位,而非人机竞技。长期以来,国内教育的一大痛点是资源不均衡:城乡师资断层、区域教研差距、个体培优成本极高。经过应试打磨的大模型,其核心价值便是填补这一空白——全天候陪伴耐心答疑、一对一错题复盘、个性化辅导方案、精准学情研判,让优质教育资源触达更多覆盖不到的地方。
但与此同时,必须警惕一种风险:不要让教育因AI擅长应试而向机器靠拢,不可让教学沦为纯粹的标准化训练。教育的复杂性,从来不是一道可以一键求解的方程——知识递进有其内在阶梯,课堂组织需要灵活应变,学生差异要求因材施教,师生之间的信任与成长更是一天天累积的结果。AI不是来简化这种复杂性的,而是帮助每一位教师、每一个学生,在这种复杂中找到属于自己的节奏和路径。
大模型的高考成绩单,不是为了证明机器比人更聪明,而是提醒我们:教育真正的火种,永远在人的手里——在教师的每一次点拨里,在学生的每一次顿悟中,在技术服务于人的每一个温暖瞬间。
文 | 记者 何宁
海报 | 黄文倩